
Tesiaren titulua: Itzulpen automatiko gainbegiratu gabea
/ Unsupervised Machine Translation
Non: Telekonferentzia: https://eu.bbcollab.com/guest/b22b606d9ae74bc5b3e067821c897617
Informatika Fakultateko Ada Lovelace Aretoan
Eguna: Uztailaren 29, asteazkena
Ordua: 11:00etan
Egilea: Mikel Artetxe Zurutuza
Zuzendariak: Eneko Agirre eta Gorka Labaka
Hizkuntza: Ingelesa / Euskara
Ikerketaren motibazioa, galderak:
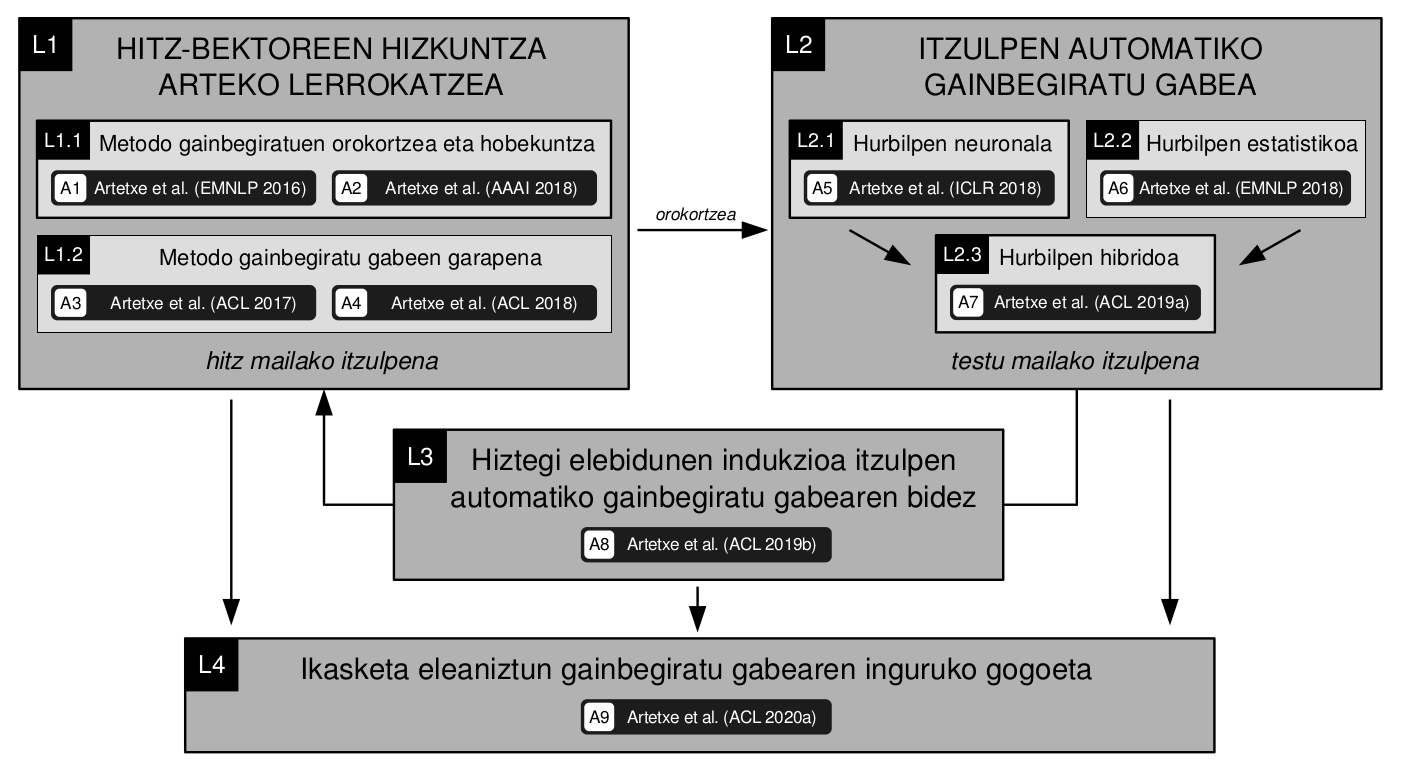
Sekuentziatik sekuentziarako eredu neuronalaren etorrerak aurrerapen izugarria ekarri du itzulpen automatikoan. Horrek hobekuntza handia ekarri du itzulpen-sistema estandarretan eta horrela zenbait ingurunetan giza-itzulpenen kalitatearen maila lortu dute lehenengoz. Hala ere, gaur egun dauden sistemek datu asko behar dute (gainbegiratze sakona), corpus paralelo gisa normalean milioika perpaus behar izaten dituzte. Baina harrigarria da, baldintza hori ez du behar gizakiak hizkuntza eskuratzeko. Eta gainera arazo praktiko garrantzitsu bat planteatzen du euskara bezalako baliabide gutxiko hizkuntzekin itzulpenak egiteko.
Tesiaren helburua datu paraleloen mendekotasun hori guztiz ezabatzea da, corpus elebakarra baino beharko ez duten “gainbegiratu gabeko itzulpen automatiko”ko sistemak eratzeko. Horretarako, lehenengo urrats batean bi hizkuntzatarako sortutako hitz-bektoreak (word embedding-ak) lerrokatzen ditu, beren arteko egitura-antzekotasunean oinarrituta. Gero, bigarren urrats batean, lerrokatze horren emaitzak erabiltzen ditu itzulpen-sistema neuronal bat edo itzulpen-sistema estatistiko bat hasieratzeko, azken urratsean back-translationaren bidez hobetzen joango dena.
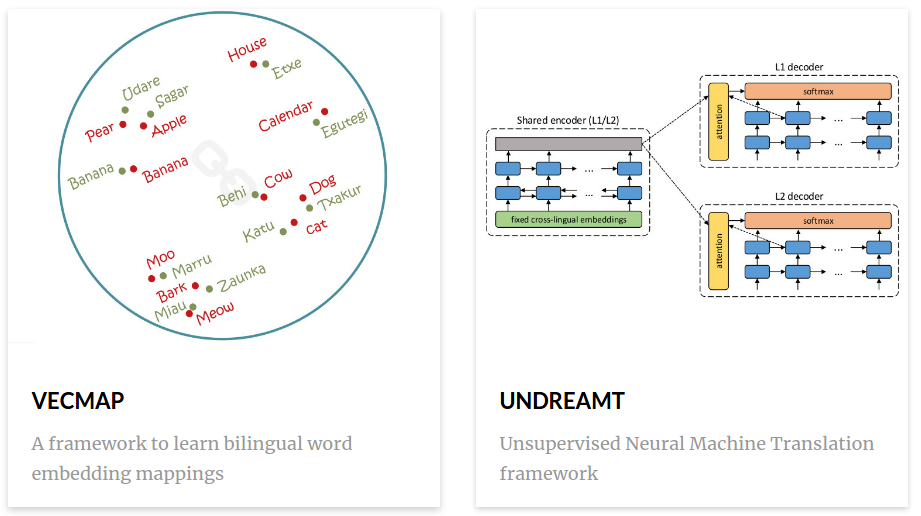
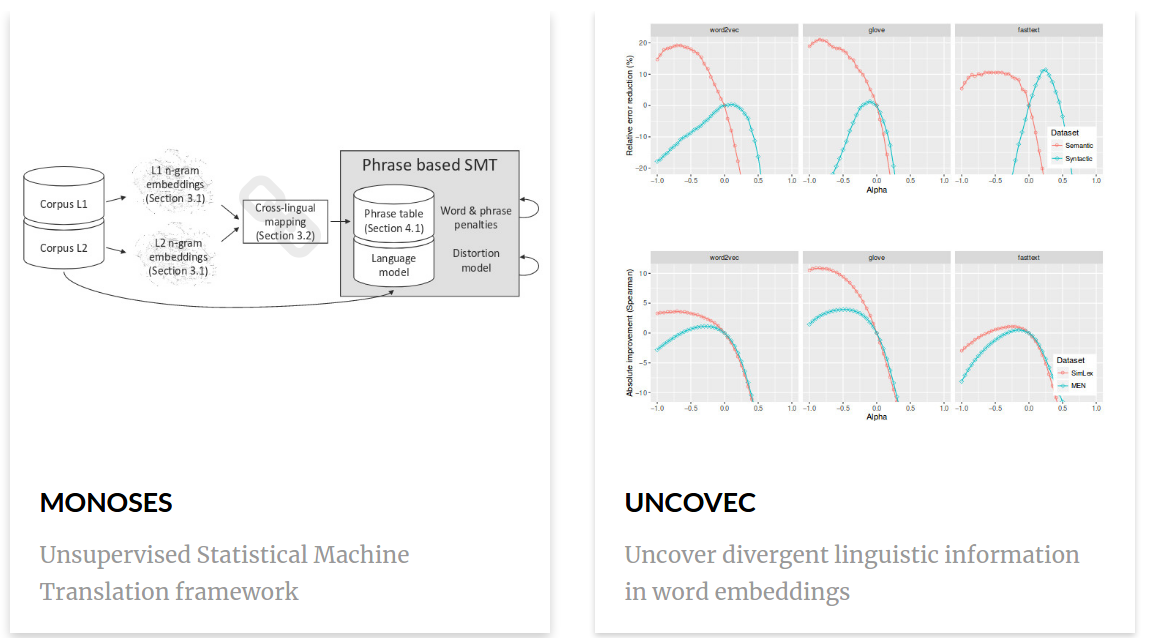
Tesiaren egindako bide progresiboa eta ekarpenak oso ondo jarraitu daiteke Mikel Artetxek 2016tik argitaratu dituen 9 artikulu hauen zehar:
- Mikel Artetxe, Sebastian Ruder, Dani Yogatama, Gorka Labaka, Eneko Agirre (2020)
A Call for More Rigor in Unsupervised Cross-lingual Learning
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics - Mikel Artetxe, Gorka Labaka, Eneko Agirre (2019)
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5002-5007.
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2019)
An Effective Approach to Unsupervised Machine Translation
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 194-203. - Mikel Artetxe, Gorka Labaka, Eneko Agirre (2018)
Unsupervised Statistical Machine Translation
In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3632–3642, Brussels, Belgium, October-November. Association for Computational Linguistics. - Mikel Artetxe, Gorka Labaka, Eneko Agirre (2018)
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics - Mikel Artetxe, Gorka Labaka, Eneko Agirre, Kyunghyun Cho (2018)
Unsupervised Neural Machine Translation
Sixth International Conference on Learning Representations (ICLR 2018) - Mikel Artetxe, Gorka Labaka, Eneko Agirre (2018)
Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) pages 5012-5019.
- Mikel Artetxe, Gorka Labaka, Eneko Agirre (2017)
Learning bilingual word embeddings with (almost) no bilingual data
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics - Mikel Artetxe, Gorka Labaka, Eneko Agirre (2016)
Learning principled bilingual mappings of word embeddings while preserving monolingual invariance
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2289–2294. Austin, Texas. ISBN: 978-1-945626-25-8.



